Visualisierung von Schnittstellen
Sind Sie für Systeme verantwortlich, die Daten speichern und diese Daten über Schnittstellen mit anderen Systemen austauschen? Und ändern sich diese Systemschnittstellen auch manchmal, z.B. durch Versionswechsel oder Formatanpassungen? Welches System ist für Ihre Daten jeweils das führende System?
Beantworten Sie diese Fragen mit „ja“? Dann erfahren Sie in diesem Beitrag wie Sie all diese Fragen auf einen Blick beantworten können. Zusätzlich haben wir eine Excel-Tabelle für Sie, die die notwendigen Daten für die Beantwortung der Fragen speichern kann.
Falls Sie diese Fragen mit „nein“ beantworten, dann können Sie in diesem Artikel erfahren, welche Fragen sich viele andere beim alltäglichen Management ihrer IT-Systeme stellen.
Kontext zur Fragestellung
Was ist eigentlich ein führendes System?
Das führende System ist das System, auf das im Falle von inkonsistenten Daten zurückgegriffen wird, um die Inkonsistenz zu bereinigen.
Beispiel: Es gibt zwei Systeme, die Kundendaten verwalten. Für ein und denselben Kunden sind in beiden Systemen unterschiedliche Adressen hinterlegt. Um zu entscheiden an welche Adresse die nächste Rechnung geschickt wird, wird auf das führende System zurückgegriffen. Das führende System sollte daher auch das System sein, in dem die Stammdaten des Kunden geändert werden. Alle anderen Systeme sollten, sofern möglich und sinnvoll, nur lesend auf diese Daten zugreifen. Es gibt also eine Schnittstelle zwischen dem führenden System und dem System, das lesend auf diese Daten zugreift. Greifen mehrere Systeme auf diese Daten zu, so gibt es auch zu diesen Systemen Schnittstellen.
Bei einer Systemveränderung können auch immer dessen Schnittstellen betroffen sein. In diesem Falle müssen alle Schnittstellen auch in den Systemen angepasst werden, die mit dem ersten System verbunden sind.
Nun besteht eine IT-Landschaft nicht nur aus einem System, das Schnittstellen zu anderen Systemen hat, sondern aus einer Vielzahl miteinander kommunizierender Systeme. Aus den Fragen zu Beginn des Beitrags und dem Beispiel zu führenden Systemen ergeben sich folgende Teilfragen:
- Welche Systeme gibt es überhaupt?
- Welche Datenobjekte gibt es in unseren Systemen?
- Welches System verwaltet (liest / schreibt) welche Daten?
- Welches System ist für welche Datenobjekte das führende System?
- Welche Schnittstellen existieren zwischen welchen Systemen?
- Welche Datenobjekte werden über welche Schnittstelle ausgetauscht?
Die Daten als Tabelle
Ich habe eine Excel-Tabelle angelegt, in der diese Informationen beispielhaft zusammengestellt sind:

Die Tabelle ist wie folgt aufgebaut (in runden Klammern die Nummer der Frage, die durch den gerade beschrieben Tabelleninhalt beantwortet wird):
Oben links ist die Liste der acht unterschiedlichen Anwendungssysteme (1) und daneben in orange die Liste der acht Datenobjekte (2). Die große Tabelle auf der rechten Seite beinhaltet in ihren ersten beiden Spalten Informationen darüber, welches System welche Daten verwaltet (3). Die dritte Spalte markiert durch ein ‚y‘ für ‚yes‘ bzw. ein ‚n‘ für ‚no‘, ob das vorne angegebene System führend für das jeweilige Datum ist (4). Das System „Order Management“ arbeitet laut Tabelle mit Daten zu Aufträgen, Mitarbeitern, Kosten und Konten (Order, Employee, Cost, Account). In der grünen Tabelle sind die Schnittstellen gespeichert, die zwischen den Systemen existieren (5). Datenobjekte werden vom Startsystem über eine automatische oder manuelle Schnittstelle (Spalte „Type“) zum Zielsystem geschickt.
Die Daten als Visualisierung
Für dieses Beispiel habe ich aus unseren Best-Practice-Visualisierungen für Enterprise Architecture Management die Matrix-Transfer-Karte ausgewählt. Sie ist genau für diese Fragestellungen entworfen worden.
Das folgende Bild zeigt eine Matrix-Transfer-Karte, die die gleichen Daten enthält, wie obige Excel-Tabelle. Auf der X-Achse werden die Anwendungssysteme als blaue Boxen und die Datenobjekte als gelbe Boxen auf der Y-Achse dargestellt. Jede grüne Box entspricht einer Tabellenzeile der lilafarbenen Tabelle von oben. Laut der ersten Tabellenzeile ist das System „Order Management“ führend für das Datenobjekt „Order“, so dass in der Grafik an der entsprechenden Schnittstelle der X-Achse und der Y-Achse eine grüne Box mit dem Eintrag „leading“ steht.
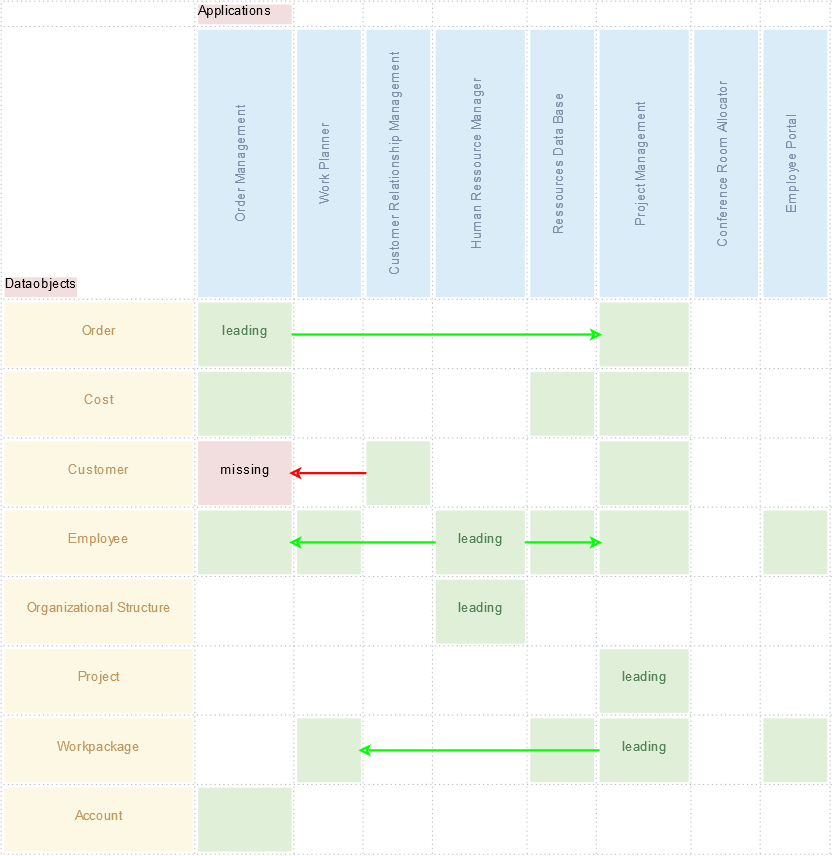
Rufen wir uns die Excel-Tabelle in Erinnerung: Die Anwendung „Order Management“ tauscht gemäß der ersten Zeile der grünen Tabelle Daten über „Order“ mit dem System „Projekt Management“ aus. Man möchte schließlich wissen, welches Projekt aus welchem Auftrag entstanden ist. In der Grafik wird das durch einen grünen Pfeil deutlich gemacht.
Dateninkonsistenzen visuell analysieren
Auf den ersten Blick erkennt man, dass eine rote Kiste „missing“ in der Visualisierung an der Stelle zwischen „Order Management“ und „Customer“ liegt. Das ist auf inkonsistente Daten zurückzuführen, die in der Excel-Tabelle leicht übersehen werden können. Analysieren wir das Problem: In der Excel-Tabelle ist in der letzten Zeile der grünen Schnittstellentabelle angegeben, dass es eine Schnittstelle zwischen „Customer Relationship Management“ und „Order Management“ gibt, über die das Datenobjekt „Customer“ übertragen wird. Soweit so gut. Es ist klar, dass alle Systeme, die in der Schnittstellentabelle Datenobjekte als Startsystem verschicken, oder als Zielsystem erhalten, diese in irgendeiner Weise verarbeiten. Diese Tatsache ist in der lilafarbenen Tabelle dokumentiert. Für das „Customer Relationship Management“ finden wir in der siebten Zeile einen entsprechenden Eintrag. Für das System „Order Management“ fehlt dieser.
Mit der Visualisierung sind wir in der Lage derartige Inkonsistenzen auf einen Blick zu erkennen.
Man kann auch leicht erkennen, dass der „Human Ressource Manager“ führend ist für „Employee“ und Daten darüber an „Order Management“ und „Project Management“ verschickt, jedoch nicht an „Work Planner“, „Ressource Data Base“ und „Employee Portal“. Warum nicht? Sind es fehlende Daten, oder werden die Informationen in den Systemen per Hand aktualisiert oder überhaupt nicht? Liegt hier Optimierungspotential in der IT-Systemlandschaft?
Attribute für eine höhere Informationsdichte
Die Visualisierung bietet einen guten Einstieg, um mit den relevanten Verantwortlichen die verschiedenen Fälle zu diskutieren.
Vielleicht reicht der Informationsgehalt noch nicht aus.
Sollen weitere Informationen gepflegt werden, bietet es sich an, Attribute zu verwenden. Hier ein paar Beispiele:
- für Anwendungsattribute:
- Lebenszyklusphase
- genutzte Version
- Hersteller
- verantwortlicher Mitarbeiter
- laufende Kosten
- für Datenobjektattribute:
- Datenformat
- Version des genutzten Datenformats
- Sind die Daten konform zu einem Industriestandard gespeichert, und wenn ja, zu welchem?
- für die Beziehung zwischen System und Daten:
- Ist das System führend?
- Sind die Daten in dem System verschlüsselt abgelegt?
- Welche Systemrollen haben Zugriff auf die Daten?
- für die Schnittstellenattribute:
- Übertragene Datenmenge in Mbyte
- Übertragungsprotokoll: HTTP(S), (S)FTP, …
- Ist es eine synchrone oder eine asynchrone Schnittstelle?
In der Visualisierung lassen sich kleine Symbole, Bilder oder Texte an den jeweiligen Kisten bzw. Pfeilen platzieren, um die Zusatzinformationen zu berücksichtigen.
Tabelle mit Attributen zur weiteren Verwendung
Die oben beispielhaft dargestellte Excel-Tabelle ist nicht mehr ausreichend, um diese Menge an Informationen abzulegen. Eine mögliche Struktur, die damit umgehen kann, könnte so aussehen:
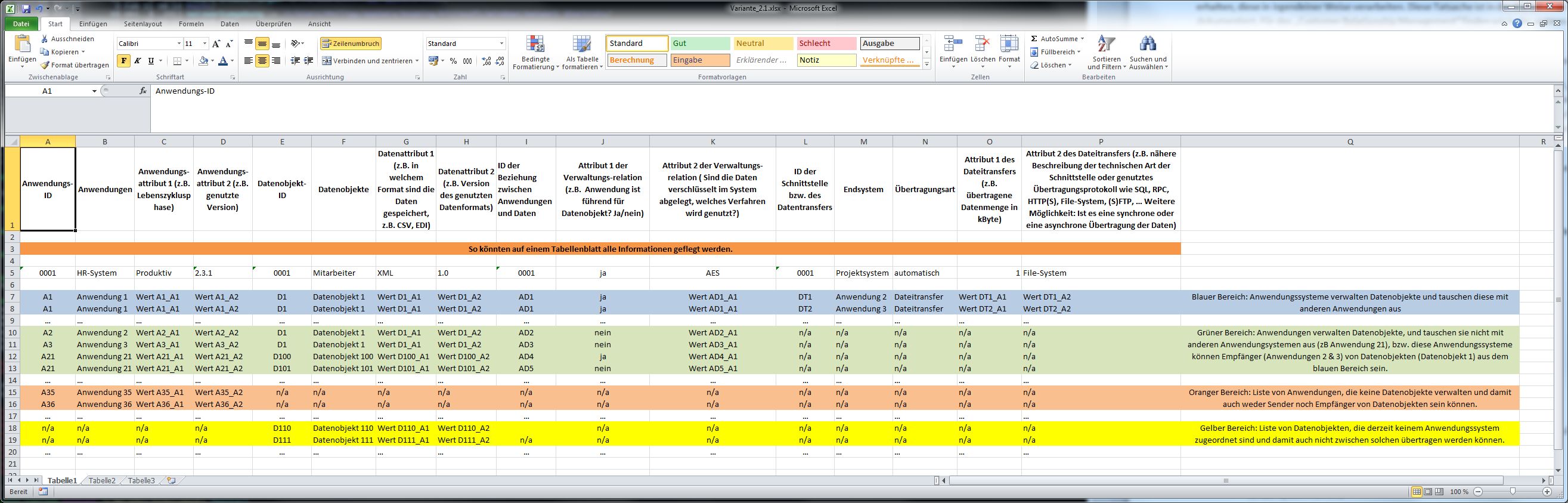
Ist so eine Struktur erstmals angelegt und mit Daten gefüllt, kann sie immer wieder auf Knopfdruck in aussagekräftige Visualisierungen übersetzt werden. Diese Tabelle können Sie auch direkt hier herunterladen und weiterverwenden.
Zusammenfassung
Daten über Schnittstellen werden häufig in Tabellen erfasst. Dieser Beitrag stellt ein Anwendungsszenario für unsere Matrix-Transfer-Karte vor, die auf Basis der Tabellendaten generiert wird. Außerdem bin ich auf die Möglichkeit eingegangen, zusätzliche Attributwerte der dargestellten Daten als Attachments mit in die Visualisierung aufzunehmen.